题目内容
【题目】在学习强国活动中,某市图书馆的科技类图书和时政类图书是市民借阅的热门图书.为了丰富图书资源,现对已借阅了科技类图书的市民(以下简称为“问卷市民”)进行随机问卷调查,若不借阅时政类图书记1分,若借阅时政类图书记2分,每位市民选择是否借阅时政类图书的概率均为![]() ,市民之间选择意愿相互独立.
,市民之间选择意愿相互独立.
(1)从问卷市民中随机抽取4人,记总得分为随机变量![]() ,求
,求![]() 的分布列和数学期望;
的分布列和数学期望;
(2)(i)若从问卷市民中随机抽取![]() 人,记总分恰为
人,记总分恰为![]() 分的概率为
分的概率为![]() ,求数列
,求数列![]() 的前10项和;
的前10项和;
(ⅱ)在对所有问卷市民进行随机问卷调查过程中,记已调查过的累计得分恰为![]() 分的概率为
分的概率为![]() (比如:
(比如:![]() 表示累计得分为1分的概率,
表示累计得分为1分的概率,![]() 表示累计得分为2分的概率,
表示累计得分为2分的概率,![]() ),试探求
),试探求![]() 与
与![]() 之间的关系,并求数列
之间的关系,并求数列![]() 的通项公式.
的通项公式.
【答案】(1)分布列见解析,6;(2)(i)![]() ;(ⅱ)
;(ⅱ)![]() ,
,![]() .
.
【解析】
(1)独立重复试验,列出随机变量![]() 可能取值为4,5,6,7,8,再求出各可能值的概率可解得.
可能取值为4,5,6,7,8,再求出各可能值的概率可解得.
(2)(i)总分恰为![]() 分的概率
分的概率![]() 是等比数列,用基本量计算.
是等比数列,用基本量计算.
(2)(ⅱ)递推数列化为等比数列求解.
(1)![]() 的可能取值为4,5,6,7,8,
的可能取值为4,5,6,7,8,
![]()
![]()
![]() ,
,![]()
![]()
所有![]() 的分布列为
的分布列为
| 4 | 5 | 6 | 7 | 8 |
|
|
|
|
|
|
所以数学期望![]() .
.
(2)(i)总分恰为![]() 分的概率为
分的概率为![]() ,
,
所以数列![]() 是首项为
是首项为![]() ,公比为
,公比为![]() 的等比数列,
的等比数列,
前10项和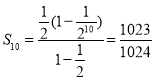 .
.
(ii)已调查过的累计得分恰为![]() 分的概率为
分的概率为![]() ,得不到
,得不到![]() 分的情况只有先得
分的情况只有先得![]() 分,再得2分,概率为
分,再得2分,概率为![]() .
.
因为![]() ,即
,即![]() ,
,
所以![]() ,
,
则![]() 是首项为
是首项为![]() ,公比为
,公比为![]() 的等比数列,
的等比数列,
所以![]() ,
,
所以![]() .
.

【题目】由于研究性学习的需要,中学生李华持续收集了手机“微信运动”团队中特定20名成员每天行走的步数,其中某一天的数据记录如下:
5860 6520 7326 6798 7325 8430 8215 7453 7446 6754
7638 6834 6460 6830 9860 8753 9450 9860 7290 7850
对这20个数据按组距1000进行分组,并统计整理,绘制了如下尚不完整的统计图表:
步数分组统计表(设步数为![]() )
)
组别 | 步数分组 | 频数 |
|
| 2 |
|
| 10 |
|
|
|
|
| 2 |
|
|
|
(Ⅰ)写出![]() 的值,并回答这20名“微信运动”团队成员一天行走步数的中位数落在哪个组别;
的值,并回答这20名“微信运动”团队成员一天行走步数的中位数落在哪个组别;
(Ⅱ)记![]() 组步数数据的平均数与方差分别为
组步数数据的平均数与方差分别为![]() ,
,![]() ,
,![]() 组步数数据的平均数与方差分别为
组步数数据的平均数与方差分别为![]() ,
,![]() ,试分别比较
,试分别比较![]() 与以
与以![]() ,
,![]() 与
与![]() 的大小;(只需写出结论)
的大小;(只需写出结论)
(Ⅲ)从上述![]() 两个组别的数据中任取2个数据,记这2个数据步数差的绝对值为
两个组别的数据中任取2个数据,记这2个数据步数差的绝对值为![]() ,求
,求![]() 的分布列和数学期望.
的分布列和数学期望.
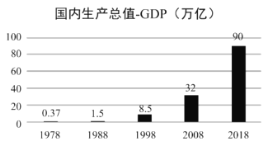
【题目】根据国家统计局数据,1978年至2018年我国GDP总量从0.37万亿元跃升至90万亿元,实际增长了242倍多,综合国力大幅提升.
将年份1978,1988,1998,2008,2018分别用1,2,3,4,5代替,并表示为![]() ;
;![]() 表示全国GDP总量,表中
表示全国GDP总量,表中![]() ,
,![]() .
.
|
|
|
|
|
|
3 | 26.474 | 1.903 | 10 | 209.76 | 14.05 |
(1)根据数据及统计图表,判断![]() 与
与![]() (其中
(其中![]() 为自然对数的底数)哪一个更适宜作为全国GDP总量
为自然对数的底数)哪一个更适宜作为全国GDP总量![]() 关于
关于![]() 的回归方程类型?(给出判断即可,不必说明理由),并求出
的回归方程类型?(给出判断即可,不必说明理由),并求出![]() 关于
关于![]() 的回归方程.
的回归方程.
(2)使用参考数据,估计2020年的全国GDP总量.
线性回归方程![]() 中斜率和截距的最小二乘法估计公式分别为:
中斜率和截距的最小二乘法估计公式分别为:
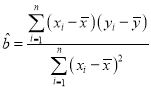 ,
,![]() .
.
参考数据:
| 4 | 5 | 6 | 7 | 8 |
| 55 | 148 | 403 | 1097 | 2981 |