6.期望和方差各是什么?
在实际问题中,除了离散型随机变量的分布列之外,我们有时还要了解随机变量更多的特征.期望和方差就是用来刻画随机变量数字特征的重要参数.期望主要用来描述随机变量的平均取值情况,而方差则用来描述随机变量的取值对于平均值的离散程度.作为随机变量重要的数字特征,期望和方差直观、综合地反映出了变量取值的大致情况,在实际中具有广泛的应用.
先来看期望,期望有时又称为数学期望或平均数等等.它表明了随机变量取值的平均水平,我们用下面的例子来引出数学期望的数学定义.
一个车间共有5台机床,对于这些机床,由于各种原因,时而工作,时而停止.因此任一时刻工作着的机床数目是一个随机变量,为了精确估计该车间的电力负荷,我们需要知道车间中同时工作着的机床的平均数目.
假定我们进行了20次观察,结果如下表所示:
|
工作着的机床数目 |
0 |
1 |
2 |
3 |
4 |
5 |
|
频数 |
0 |
0 |
1 |
2 |
6 |
11 |
|
频率 |
0 |
0 |
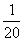 |
 |
 |
 |
表1-13
因此,该车间中同时工作着的机床的平均数目为:

由上面的计算过程可知,所求的平均数实际上就是随机变量的可能取值与取该值时对应的频率乘积之和.由于这个平均值是由观察得来的,所以会带有-些偶然性,这种偶然性主要表现在频率上.如果我们能用概率代替频率,就能从根本上消除这种偶然性,从而在本质上反映出随机变量的平均值.为此,我们将期望定义为如下的值:
一般地,设随机变量η的分布列为:
|
η |
 |
 |
 |
… |
 |
… |
|
P |
 |
 |
 |
… |
 |
… |
表1-14
我们定义 为离散型随机变量η的数学期望,简称期望.[注:一个随机变量的期望是一个确定的值,如果它存在的话,应与等号右边的求和顺序无关.]
为离散型随机变量η的数学期望,简称期望.[注:一个随机变量的期望是一个确定的值,如果它存在的话,应与等号右边的求和顺序无关.]
根据数学期望的定义,我们可得关于期望的两条重要的性质:
性质一:对于任何常数c,公式E(cη)=c·Eη恒成立.[注:一般地,随机变量η的期望可以成E(η)简记为Eη,但若η前有系数时,必须写成E(kη),k为常数系数.]
性质二:对于多个随机变量 ,若它们的期望都存在,则下式成立.
,若它们的期望都存在,则下式成立.

下面列举几个常用分布的期望值:
(1)服从两点分布的随机变量η的期望值为Eη=P.(其中P为η取1时的概率).
(2)服从二项分布的随机变量η的期望值为Eη=n·P.(其中P为事件成功的概率).
(3)服从几何分布的随机变量η的期望值为 .(其中P为事件成功的概率).
.(其中P为事件成功的概率).
由上面的实例可知,期望在实际应用中很重要.但在不少问题中,仅仅知道了随机变量的期望是不够的.比如,考查射手打靶射击的水平,不仅要看他们各自平均击中的环数,而且还应看他们所击中环数的摆动程度.假定两名射手各自射击5次,所得环数如下表:
|
射击次数 |
1 |
2 |
3 |
4 |
5 |
|
甲击中的环数 |
4 |
8 |
7 |
10 |
6 |
|
己击中的环数 |
7 |
7 |
8 |
7 |
6 |
表1-15
容易计算甲、乙二人射击的平均环数都是7环,但很明显击中环数与平均击中环数的偏离程度不一样.从稳定性来看乙要好于甲.把随机变量的这种特性用一个数字表示出来就有了方差的概念.我们来看看方差的定义.对于上述例题我们可以先计算每次击中的环数与平均击中环数的差的平方:

然后分别对它们求均值:
对甲有:(9+1+0+9+1)÷5=4.
对乙有:(0+0+l+0+1)÷5=0.4.
显然0.4<4,即乙射手的射击稳定性要优于甲射手.
在这里为什么我们要用实际取值与平均取值的差的平方参与运算而不用差本身呢?这是因为差本身可能由于有正有负而相互抵消,那就不能正确反映出偏离程度了,而用差的平方就-定可以避免这种情况发生.
上面例中的实际取值与均值的差的平方和的平均值我们叫做方差.方差是用来描述随机变量取值的偏离程度的量.对于随机变量η,方差记为 ,显然表示
,显然表示 的平均值,也就是
的平均值,也就是 ,这就是方差的数学定义.根据我们已知的期望的运算法则有:
,这就是方差的数学定义.根据我们已知的期望的运算法则有:

在实际计算过程中,我们经常用上面推出的等式: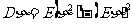 来计算方差.和期望一样,方差也有两条常用的性质:
来计算方差.和期望一样,方差也有两条常用的性质:
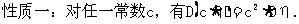
性质二:对于互相独立的随机变量,成立
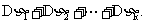
一些常用概率分布的方差如下:
(1)两点分布的随机变量的方差为:Dη=p·(1-p).
(2)服从二项分布的随机变量的方差为:Dη=n·p·(1-p).
 .
.
[注:除了方差外,我们还可能用到 ,一般用希腊字母σ来表示,称为随机变量η的标准差,它也是描述随机变量取值离散程度的重要参数.]
,一般用希腊字母σ来表示,称为随机变量η的标准差,它也是描述随机变量取值离散程度的重要参数.]




12.如何度量给定数据组的中心趋势和离散程度?
资本家和工会公开辩论工人的工资,工会报告说,工人每年拿到的工资平均只有3000元,而资本家却说工人的年平均工资为7300元,到底谁的话更可信呢?
在作出判断之前,我们先来看一下用来计算上述结果的工人工资数:3000,3000,3000,3500,4000,4500,6000,6000,15000和25000,在所有这些工资中,哪一层次的最普遍呢?也就是说,在上面所列的工资中,工人拿哪一种工资的人最多?在数据集合中,我们称出现最多的数字为“众数”.在上面给出的集合中,众数是3000.
用以代替所考虑的最常出现的工资数,我们把所有工人的工资放在-起求平均数,这样得到的是这组数据的平均数,一般用“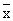 ”表示.即:对给定的数据
”表示.即:对给定的数据 ,有下列公式
,有下列公式 .按公式可以计算我们给定的工资集合的平均数
.按公式可以计算我们给定的工资集合的平均数 元.那么7300元是不是对工人平均工资的合理的估计呢?
元.那么7300元是不是对工人平均工资的合理的估计呢?
有时,用来估计数据集合的中心趋势的另一个数是中位数.把一组数据按从小到大的顺序排列.然后取中间的一个数,它就是中位数.如果数据的个数是偶数,那么中位数就取中间两个数的平均数.那么上述工资数据的中位数是多少呢?易得这组数据的中位数是4250,那么在3000,4250,7300这三个数中,哪一个看上去是平均工资的最好估计呢?
上面讲的众数、平均数和中位数可统称为平均.一般情况下,如果有人告诉你某一数据集合的平均是某个数,而没告诉你它是一个什么样的平均,则这个信息就没有太大的作用.一般来说,即使告诉了你别人用了哪种平均方法,掌握更多的资料比只知道平均更为有价值.
例如,除了知道平均数为7300元以外,我们又知道它由10个人的工资所平均,这样的话,工资总数为73000元.当然,工资总数并不能告诉你工资是如何分配的,这对工会来说似乎是最重要的问题,如果有一份工资为50000元,(例如经理的工资),那么分给其他9个人的工资就不会太多.换一种情况,如果最高工资为8000元,那么大多数雇员一定会得到7000元左右的工资.这样,很清楚,如果与平均工资一起报出最高和最低工资,我们就能对上述两种说法有比较公正的看法了.
如果不是告诉读者最高和最低工资,而是给出了最高和最低工资之差(称为极差),对于精明的读者,仍然能找到许多有用的信息.例如,如果10份工资的平均数是7300元,极差是22000元,我们就能断定最高工资至少是22000元,更可能是24000元或25000元,因为最少的工资几乎可以肯定会是2000元或多一些.因此有如果10个人的平均工资是7300元,总工资应为73000元.如果一个人的工资大约是24000元,那么其他9个人的总工资应为49000元,9人的平均工资约为5444元.
一个数据集合的极差是这组数据离散程度的度量,可是,极差仅仅依赖于数据两端的值.它没有给出关于这两个端点间数据离散程度的任何信息.
对一个数据集来说,任何一个数据 对平均数的离差为
对平均数的离差为 使用前面关于工资的数据(它的平均数为7300元),我们计算3000对于平均数的离差:
使用前面关于工资的数据(它的平均数为7300元),我们计算3000对于平均数的离差: 再计算15000对于平均数的离差:
再计算15000对于平均数的离差: 注意到3000对于的离差为负.而15000对于的离差为正.计算其余的每一工资数对于的离差有:
注意到3000对于的离差为负.而15000对于的离差为正.计算其余的每一工资数对于的离差有:
|
|
3000 |
3500 |
4000 |
4500 |
6000 |
15000 |
25000 |
 |
-4300 |
-3800 |
-3300 |
-2800 |
-1300 |
7700 |
17700 |
表1-26
由上表可知,所有工资数对于的离差之和为0.
事实上,任何一组数据对平均数的离差之和总是0.因此,不能用对平均数的离差来描述这组数据的离散程度.因为对平均数离差的总和没有给出关于这一数据集合的离散程度的任何信息.
可是,我们可以考查对平均数离差的绝对值,由于一个数的绝对值不会是负数,并且除非对所有的有 ,否则对平均数的离差的绝对值之和就不会是0.就上述工资的数据来计算这个和,我们得到40900,这个和也不是关于数据离散程度的满意的度量,因此我们用测量数据的个数去除40900,得到4090这个值称为平均离差,它常用来度量数据的离散性.
,否则对平均数的离差的绝对值之和就不会是0.就上述工资的数据来计算这个和,我们得到40900,这个和也不是关于数据离散程度的满意的度量,因此我们用测量数据的个数去除40900,得到4090这个值称为平均离差,它常用来度量数据的离散性.
虽然数据的平均离差能对数据的离散性进行可靠、合理的度量,但在更高级的数学处理中,绝对值的运算常常会带来一些问题(尤其对大量数据而言).因此,我们常采用所谓标准差来作为离散性的度量.
经过上面的叙述可以知道,之所以使用绝对值函数,主要考虑到它是正的,也就是说,我们只需要考虑绝对值的大小.具有同样性质的另一种函数是将离差平方.这种作法构成了下面标准差概念的基础.
定义:已知 是一组观测值.是这组观测数据的平均数,则该组数据的标准差为:
是一组观测值.是这组观测数据的平均数,则该组数据的标准差为: 标准差的平方与标准差本身是一样方便的,标准差的平方
标准差的平方与标准差本身是一样方便的,标准差的平方 称为方差.
称为方差.
关于上面工资数据的离差和离差的平方如下表:
|
|
 |
 |
|
3000 3500 4000 4500 6000 15000 25000 |
-4300 -3800 -3300 -2800 -1300 770 1770 |
18490000 14440000 10890000 7840000 1690000 59290000 313290000 |
|
73000 |
0 |
464600000 |
表1-27
一个用以简化计算标准差的等价公式是:

为了推导这个公式,我们来考查方差的公式:

将和式中每一个二项式平方后得到:

整理后得到:


在上式两端取平方根就得到
因为上面的公式和关于标准差的原公式是等价的,所以如果觉得哪个方便就用哪个.例如计算3,5,8,13的标准差,用所推导的公式计算如下:

而运用原公式,我们计算如下:


11.如何对大量的原始数据进行数据分组?
当碰到大量原始数据时,把这些数据按适当的区间分组是方便的.为了便于计数,希望所选择的每个区间的中点是诸如5或10的倍数.一般区间数应不少于10个而不多于25个.区间的边界值通常应比原始数据中出现的小数位数多一位,以便使得每一个数据仅包含在一个区间之内.
假定下面的数据是有50个高中学生的一个班在某次数学测验中所得到的分数:
88 74 67 49 69 38 86 77 66 75 94 67 78 69 84 50 39
58 79 70 90 79 97 75 98 77 64 69 82 71 65 68 84 73
58 78 75 89 91 62 72 62 74 81 79 81 86 78 90 81
乍一看这些分数就知道,最低分为38,最高分为98.于是,如我们要把数据分组,使区间中点为5的整倍数,可分为13个区间,它满足大于10小于25的条件.为了保证每个数据仅被包含在一个区间内,区间的边界确定到小数点后一位.这就得出下面的数学测验得分的分组频数表.
|
区间 |
区间中点 |
频数 |
频数百分数 |
累积频数 |
累积频数百分比 |
|
37.5-42.5 42.5-47.5 47.5-52.5 52.5-57.5 57.5-62.5 62.5-67.5 67.5-72.5 72.5-77.5 77.5-82.5 82.5-87.5 87.5-92.5 92.5-97.5 97.5-102.5 |
40 45 50 55 60 65 70 75 80 85 90 95 100 |
2 0 2 0 4 5 7 8 10 4 5 2 1 |
4 0 4 0 8 10 14 16 20 8 10 4 2 |
2 2 4 4 8 13 20 28 38 42 47 49 50 |
4% 4% 8% 8% 16% 26% 40% 56% 76% 84% 94% 98% 100% |
表1-23
为了从图形上说明分组数据的频数分布,我们用频数直方图来代替点频数图.直方图是一种条线图,其中每一个矩形的底表示一个区间,高表示在给定的区间内观测数据的个数.上述数学测验得分分组直方图如图1-6所示:

对未分组的数据作出的累积图给出了累积分布.对分组数据,我们叫做累积折线,也叫尖顶图.这个图的作法是:折线上的点的横坐标取所在区间的右边界,纵坐标取相应的累积频数,然后把所确定的点用线段连接起来,横坐标为第一个区间的左边界、纵坐标为零的点,也包括在累积折线内.如图1-7所示:

这样,对于累积折线上的任何一点,纵坐标给出了少于或等于横坐标的观察数据的数目.从前面给出的数学测验的累积折线图上可以看到,少于或等于91分的大约为45人.
像在累积图上一样,也可用同样的方法在累积折线上决定百分位数.例如,在上图中可以读出,中位数为76;25百分位数是67;75百分位数是82.
前面的问题介绍了频数表和频数分布.这个问题中又介绍了如何对数据进行分组,让我们来看一道例题说明前面这些图表的作法.
例 下面是30个灯泡的寿命(单位:小时)
870 840 920 950 960 810 830 860
900 800 940 920 850 840 880 810
950 840 830 910 970 930 870 930
900 980 910 930 970 880
试作出这组数据的总频数图和累积图.另外把这些数据按区间795-815,815-835,835-855,…,975-995分组.作出其频数表、直方图和累积折线.
思路启迪
为了作出点频数图和累积图,我们先做出这组数据的频数
表如下所示:
|
寿命 |
频数 |
寿命 |
频数 |
|
800 810 820 830 840 850 860 |
1 2 0 2 3 12 1 |
900 910 920 930 940 950 960 |
2 2 2 3 1 2 1 |
|
870 880 890 |
2 2 0 |
970 980 990 |
2 1 0 |
表1-24
有了上面的频数表,我们很容易作出点频数图和累积图.
规范解法 根据所给数据的频数表我们可以作出点频数图和累积图如下所示:


按给定的分组可得频数表、直方图和累积折线分别如下:
|
区间 |
区间中点 |
频数 |
频数百分比 |
累积频数 |
累积频数百分比 |
|
795-815 |
805 |
3 |
10 |
3 |
10 |
|
815-835 |
825 |
2 |
6.7 |
5 |
16.7 |
|
835-855 |
845 |
4 |
13.3 |
9 |
30 |
|
855-875 |
965 |
3 |
10 |
12 |
40 |
|
875-895 |
885 |
2 |
6.7 |
14 |
46.7 |
|
895-915 |
905 |
4 |
13.3 |
18 |
60 |
|
915-935 |
925 |
5 |
16.7 |
23 |
76.7 |
|
935-955 |
945 |
3 |
10 |
26 |
86.7 |
|
955-975 |
965 |
3 |
10 |
29 |
96.7 |
|
975-995 |
985 |
1 |
3.3 |
30 |
100 |
表1-25

10.什么是频数表和频数分布?
假定某个数学班的学生的身高(单位:厘米)如下:
164 173 168 168 176 170 162 167 171 169
168 160 165 168 166 168 167 171 166 172
用这种形式给出的数据难以说明什么问题.如果把它们加以整理,就比较容易说明问题了.例如,我们可以按照递增和递降的顺序来排列身高,这叫做排序.于是我们很容易看出:160是最小身高,176是最大身高,身高为168或低于168的约占半数,所测量的最大值和最小值之差称为极差.下面是按递增顺序对身高的排序:
160 166 168 168 171
162 166 168 169 172
164 167 168 170 173
165 167 168 171 176
整理数据的-个更为有用的方法是频数表,它给出了每一类的频数.如下表所示:
|
身高 |
频数 |
身高 |
频数 |
|
160 161 162 163 164 165 166 167 168 |
1 0 1 0 1 1 2 2 5 |
169 170 171 172 173 174 175 176 177 |
1 1 2 1 1 0 0 1 0 |
表1-22
另外,常用的还有点频数图.点频数图是-种表示数据在极差范围内是怎样散布的图形,本例中我们看到身高似乎集中在168左右.如图1-4所示:

频数表和点频数图都用来表示数据的分布或频数分布.需要注意的是,频数分布是一个函数,即每个观察值与它的频数相对应.这样,-个频数可以用表示一个函数的三种方式的任何-种来表示:用表、用图或用一个规则(有时是解析式).在描述数据时,通常用表(频数表)或图(例如点频数图等).可是,为了描述一种理论频数分布,有时必须要说明给出函数的规则.
有时,把数据整理成另一种分布──所谓的累积频数分布图──是方便易行的,如图1-5所示:

这种分布图给出了每一观察值与不大于该观察值的频数之间的关系,从图形上看,累积频数分布用一种累积图来表示.横轴上的数表示身高,纵轴左边的数表示累积频数.而右边的数表示累计频数的百分比.于是,每一个纵坐标给出了少于或等于相应横坐标上身高的频数或百分数,从上面的累积图显然看出,身高少于或等于167厘米的频数是8,百分比是
40%.
累积图上纵坐标为P,百分数的点所对应的横坐标叫做P百分位数.例如,90百分位数是172.这意味着90%的人的身高小于或等于172厘米.50百分位数称为中位数,25百分位数称为下四分位数,而75百分位数称为上四分位数.
 由于
由于 是对随机变量X观察的结果,且各次观察的结果是在相同条件下独立进行的,所以有理由认为
是对随机变量X观察的结果,且各次观察的结果是在相同条件下独立进行的,所以有理由认为 它是一组实数,称为样本值.
它是一组实数,称为样本值.4.离散型随机变量分布列有什么应用?
离散型随机变量的分布列是用来表示离散型随机变量取各个值的可能性大小的表格.一般地,对于离散型随机变量η,其分布列为:
 |
 |
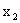 |
 |
… |
 |
… |
|
P |
 |
 |
 |
… |
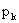 |
… |
表1-8


所有离散型随机变量的分布列中的各概率值都必须满足上面两个条件.
问题一:判断某一数列是否可以成为某一离散型随机变量的分布列.
离散型随机变量的分布列又可称为离散型随机变量的概率分布列.对于一个已知的数列,我们可以由条件一和条件二来判断它是否可以成为一个离散型随机变量的分布列.
例1 设η为一个离散型随机变量,下列选项中可以作为η的分布列的是 ( )
 B.0.1,0.2,0.3,0.4
B.0.1,0.2,0.3,0.4


思路启迪:对于四个选,我们可以分别用分布列成立的条件一和条件二来判断.同时满足这两个条件的选项才能作为η的分布列.
规范解法 先来判断选项A,因为数列 ,1,
,1, 中含有负数,不满足条件一.所以不能作为η的分布列.
中含有负数,不满足条件一.所以不能作为η的分布列.
选项B中,数列0.1,0.2,0.3,0.4均为正数且和为1,所以可以作为η的分布列.
对于选项C和选项D,都含有无穷项,且每一项都是正数,满足条件一.但是在选项C中,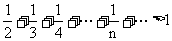 ,故C中的数列不能做为η的分布列;而在选项D中,
,故C中的数列不能做为η的分布列;而在选项D中, ,故选项D中的数列
,故选项D中的数列 也可作为η的分布列.
也可作为η的分布列.
问题二:给定的分布列中含有未知常数,该如何求它?
有的时候,我们遇到的分布列中,随机变量η取各可能值的概率与某一未知数有关,这时我们可以用分布列存在的条件一和条件二来确定题目中的未知数.
点评:离散型随机变量的取值可以是有限个也可能是无限个,因此其分布列可以是有限数列也可能是无穷数列.
例2 设离散型随机变量η的分布列为:
|
η |
1 |
2 |
3 |
4 |
5 |
6 |
|
P |
 |
 |
 |
|
|
|
表1-9
试确定分布列中的未知常数a.
思路启迪 由题目可知,随机变量η可能取的值为1,2,3,4,5,6六个值.取每个值的概率由未知数a来表示,这时我们可以用条件二来求a的值.
规范解法 由题设可知,数列,,,,,是随机变量η的分布列,所以下式成立:

解之得 ,因而随机变量η的分布列应为:
,因而随机变量η的分布列应为:
|
η |
1 |
2 |
3 |
4 |
5 |
6 |
|
P |
 |
 |
 |
|
|
|
表1-10
问题三:如何根据随机变量的分布列来计算给定事件发生的概率?
对于这类问题,其目的往往是让我们计算随机变量η落在某一区间内的概率.主要方法是将题目中要求计算的事件的概率用分布列表示出来,然后再利用概率的运算法则加以计算.
例3 设随机变量η的分布列为:
|
η |
-1 |
2 |
3 |
|
P |
 |
|
|
表1-11

思路启迪
首先要知道事件 和事件
和事件 各包含哪些基本事件.由η的分布列可知,η可能取的值为-1,2,3,事件包含基本事件{η=-1},所以
各包含哪些基本事件.由η的分布列可知,η可能取的值为-1,2,3,事件包含基本事件{η=-1},所以 同理可求出
同理可求出
规范解法 由随机变量,η的分布列可知,因为事件只包含基本事件{η=-1},
同理,事件 包含基本事件{η=2}和{η=3},所以
包含基本事件{η=2}和{η=3},所以

点评 计算给定的事件的概率的关键是看它所包含的基本事件的数目,然后将各基本事件发生的概率相加就得到我们要求的事件的概率.
例4 设自动生产线在调整后出现废品的概率为0.1,而且一旦出现废品就要重新调整,求在两次调整之间所生产的合格品的数目不小于5的概率.
思路启迪 如果用随机变量η表示两次调整之间生产的产品的个数,而且我们知道一旦出现废品就重新调整生产线,所以两次调整之间所生产的合格品是连续出现的,那么随机变量η的取值就服从几何分布,我们在解题时应先求出η的分布列.然后再计算事件“合格品数不小于5”即{η>5}的概率.
规范解法 设随机变量η表示两次调整之间生产线所生产的产品的个数,则η服从几何分布,事件{η=k}就表示生产了k-1件合格品,且第k件产品是废品.容易求得:
P(η=1)=0.1,
P(η=2)=(1-0.1)×0.1=0.09,

写成分布列的形式为:
|
|
1 |
2 |
3 |
4 |
5 |
6 |
… |
|
P |
0.1 |
0.09 |
0.81 |
0.0729 |
0.06561 |
0.059049 |
… |
表1-12
题目中要求计算“所生产的合格品数不小于5”的概率,即P(η>5),因为事件{η>5}所包含的基本事件为{η=6},{η=7},…,{η=n},…,所以有
P(η>5)=P(η=6)+P(η=7)+…+P(η=n)+…
我们应用分布列的性质计算上式的值.因为P(η>5)=1-P(η≤5),所以
P(η>5)=1-[P(η=1)+P(η=2)+P(η=3)+P(η=4)+P(η=5)]
=1-(0.1+0.09+0.081+0.0729+0.06561)
=0.49049,
所以事件“两次调整之间所生产的合格品数不小于5”的概率为0.49049.
点评 这是一道综合例题,包括了分列的计算及分布列的应用两个步骤.该题对于我们巩固所学知识,深入了解分布列有很大帮助.
3.离散型随机变量的分布规律是如何表示的?
要想掌握离散型随机变量的统计规律性,必须要知道它所有可能取的值及取每一个值的概率.将这些信息用表格形式表达出来就得到了离散型随机变量的分布列.设离散型随机变量η的所有可能的取值为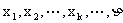 取每一个值的概率为
取每一个值的概率为 (k=1,2,…),则η的分布列可表示为表1-1.
(k=1,2,…),则η的分布列可表示为表1-1.
|
η |
 |
 |
… |
|
… |
|
P |
|
|
… |
 |
… |
表1-1
由表1-1可以看出,求η的分布列的主要任务是计算η取各个值时的概率,我们可以通过以下方法来求.
(1)利用古典概率的计算方法算出事件 (k=1,2,…)的概率.古典概率又称等可能概率,具有以下两个特点:
(k=1,2,…)的概率.古典概率又称等可能概率,具有以下两个特点:
①试验的结果有有限个;
②试验中每个结果出现的可能性相同.
由这两个限定条件可知掷硬币和掷骰子的试验是古典概率问题.如果设古典概率问题的结果数为n,则很容易知道随机变量取任一结果的概率都是 .
.
(2)根据有关分布的概率计算公式来计算事件的概率.
我们常见的一些简单分布有两点分布、二项分布和几何分布等.它们各自有不同的特点.
①两点分布:对于一个随机试验,如果它的结果只有两种情况,则我们可用随机变量

来描述这个随机试验的结果.如果甲结果发生的概率为P,则乙结果发生的概率必定为1-P,所以两点分布的分布列为表1-2.
|
|
1 |
0 |
|
P |
P |
1-p |
表1-2
②二项分布:二项分布是两点分布的推广.二项分布同时满足以下四个条件:
Ⅰ.每次试验都只有两种结果:成功或失败;
Ⅱ.共进行n次试验,n为给定的正整数;
Ⅲ.各次试验互相独立;
Ⅳ.任何一次试验中成功的概率都是一样的.
如果我们设在每次试验中成功的概率都为P,则在n次重复试验中,试验成功的次数是一个随机变量,用ξ来表示,则ξ服从二项分布.则在n次试验中恰好成功k次的概率为:

所以二项分布的分布列为表1-3:
|
ξ |
0 |
1 |
… |
|
… |
n |
|
P |
 |
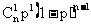 |
… |
 |
… |
 |
表1-3
③几何分布:重复进行独立试验,每次试验只有成功、失败两种可能,如果每次试验成功的概率为p,重复试验直到出现一次成功为止,则需要的试验次数是一个随机变量,用ξ表示,因此事件{ξ=n}表示“第n次试验成功且前n-1次试验均失败”.所以 ,其分布列如表1-4所示:
,其分布列如表1-4所示:
|
ξ |
1 |
2 |
… |
n |
… |
|
P |
p |
p(1-p) |
… |
 |
… |
表1-4
除了这三种简单的分布外,还有超几何分布和泊松分布等,这里就不一一列举了.
(3)根据离散型随机变量的分布函数也可以确定其分布列.
现对上面几种方法分别举例说明:
例1 将一个骰子连续投掷两次,以随机变量η表示两次所掷点数之和,请写出随机变量η的分布列.
思路启迪 一个骰子连掷两次,两次出现的点数相互独立,因此基本事件总数可用重复排列公式计算,应为 .η表示两次所得总数之和,则η的所有可能取值为2,3,4,…,12.为了计算P(η=k),则必须先求出{η=k}所包含的基本事件数.其基本事件数为满足k=m+n(m≤6,n≤6,m,n为自然数)的m和n的所有正整数解的个数,并且每个基本事件发生的概率都为
.η表示两次所得总数之和,则η的所有可能取值为2,3,4,…,12.为了计算P(η=k),则必须先求出{η=k}所包含的基本事件数.其基本事件数为满足k=m+n(m≤6,n≤6,m,n为自然数)的m和n的所有正整数解的个数,并且每个基本事件发生的概率都为 .
.
规范解法 因为{η=2}={第一、二次出现的点数均为1},故
{η=3}={第一次出现1点,第二次出现2点}+{第一次出现2点,第二次出现1点},事件{η=3}共包括两个基本事件.故

{η=4}={第一次出现1点,第二次出现3点}+{第一次出现3点,第二次出现1点}+{第一、二次均出现2点},即{η=4}共包含三个基本事件,故 .
.
一般地,设第一个骰子出现的点数为 ,第二个骰子出现的点数为
,第二个骰子出现的点数为 ,显然与相互独立,且
,显然与相互独立,且 则
则

由上式容易计算出η的分布列为:
|
|
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
|
P |
|
 |
 |
 |
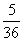 |
 |
|
|
|
|
|
表1-5
例2 某种传染病进入羊群,已知此种传染病的发病率为 ,为了检验一种新药针剂是否对此传染病有防治疗效,给50头羊注射该种针剂,结果注射后有25头羊发病,试判断针剂是否有效?
,为了检验一种新药针剂是否对此传染病有防治疗效,给50头羊注射该种针剂,结果注射后有25头羊发病,试判断针剂是否有效?
思路启迪 考虑在未注射针剂时,羊群中发病的羊的数量,因为每头羊只会出现两种情况:发病与未发病,所以发病的羊的数量服从二项分布.
规范解法 假定新药无效.将考查一头羊是否发病作为一次试验,则50头羊中发病头数η服从二项分布.即:
由 ,可得η的分布列的部分值如下:
,可得η的分布列的部分值如下:
|
|
≤20 |
21 |
22 |
23 |
24 |
25 |
≥26 |
|
P |
0.0001 |
0.0002 |
0.0005 |
0.0012 |
0.0028 |
0.0059 |
0.9893 |
表1-6
由此可得P(η≤25)=0.0107,即事件“发病羊的数目少于26头”发生的概率仅为0.0107,由概率的频率解释可知,在100次试验中,这种情况才可能出现一次,这类事件我们称之为
“小概率事件”.由实际推断原理可知小概率事件在一次试验中基本不发生.也就是说,在“新药无效”的假设下推断出来的结论“发病羊的数目少于26头”几乎不会发生.这就与我们实际观察到的结果“发病率为”相互矛盾,因此推翻“新药无效”这一假设.从而该药品对羊群中的传染病确有疗效,使羊群发病率由减少到了.[注:上述推断的依据是:小概率事件在一次试验中基本不发生,推断的方法类似于通常用的反证法.]
例题中我们见到的小概率事件在生活中相当普遍.比如我们在购买彩票时,一张彩票中头奖的概率仅为十万分之一.所以买一张彩票就中头奖的事几乎不会发生.但由于我们的推断方法带有概率性质,所以我们不能说中头奖的事必然不会发生,否则买彩票就没什么意义了,这一点是概率论所研究的随机现象和我们以前数学所研究的确定性现象之间的主要区别,下面看一道例题:
例3 一篮球运动员投篮的命中率为60%,以η表示他首次投中时累计已投篮的次数,求η的分布列.
思路启迪 通过分析题目中的条件可知,事件{η=k}表示该运动员共投篮k次,第k次投中且前k-1次均未投中,所以该事件发生的概率为:

规范解法 设随机变量η表示运动员首次投中时累计已投篮的次数.易知η服从几何分布,又因为运动员投中的概率为0.6,故投不中的概率为1-0.6=0.4,从而
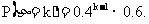
所以随机变量η的分布列为:
|
|
1 |
2 |
3 |
4 |
… |
k |
… |
|
P |
0.6 |
0.24 |
0.096 |
0.0384 |
… |
 |
… |
表1-7
点评 由上表观察,该运动员投5次时几乎总能投中,因为P(η>4)=0.0256,即事件“四次都未投中”的概率只有0.0256,属于小概率事件.


 ,ξ的取值会发生变化,并且这些量取各种值的可能性有大有小.我们称这种随结果出现的可能性大小而取这个值或那个值的变量为随机变量.概括来讲,在某一随机现象中,对于每一个随机事件,都对应惟一的一个数,这样依不同随机事件而取不同值的量就是随机变量.随机变量通常用希腊字母ξ,η来表示.
,ξ的取值会发生变化,并且这些量取各种值的可能性有大有小.我们称这种随结果出现的可能性大小而取这个值或那个值的变量为随机变量.概括来讲,在某一随机现象中,对于每一个随机事件,都对应惟一的一个数,这样依不同随机事件而取不同值的量就是随机变量.随机变量通常用希腊字母ξ,η来表示.