题目内容
一组数据共有7个数,记得其中有10,2,5,2,4,2,还有一个数没记清,但知道这组数的平均数、中位数、众数依次成等比数列,这个数的所有可能值的和为
| A.9 | B.3 | C.20 | D.-11 |
A
解析试题分析:设出未知数,根据这组数的平均数、中位数、众数依次成等差数列,列出关系式,因为所写出的结果对于x的值不同所得的结果不同,所以要讨论x的三种不同情况.设这个数为x,则可知,其平均值为10+2+5+2+4+2+x ,众数为2,若x≤2,则中位数为2,此时x=-11,
,众数为2,若x≤2,则中位数为2,此时x=-11,
若2<x<4,则中位数为x,此时2x= +2,x=3,若x≥4,则中位数为4,2×4=+2,x=17,
+2,x=3,若x≥4,则中位数为4,2×4=+2,x=17,
所有可能值为-11,3,17,其和为9.故选C
考点:中位数、众数,平均数
点评:解决的关键是根据中位数、众数,平均数的概念来得到等比数列的关系式,进而分析方程得到求解,属于基础题。

练习册系列答案
 名校课堂系列答案
名校课堂系列答案
相关题目
利用独立性检验来考虑两个分类变量X和Y是否有关系时,通过查阅下表来确定断言“X和Y有关系”的可信度。如果k>5.024,那么就有把握认为“X和Y有关系”的百分比为( )
| P(k2>k) | 0.50 | 0.40 | 0.25 | 0.15 | 0.10 | 0.05 | 0.025 | 0.010 | 0.005 | 0.001 |
| k | 0.455 | 0.708 | 1.323 | 2.072 | 2.706 | 3.84 | 5.024 | 6.635 | 7.879 | 10.83 |
以下有关线性回归分析的说法不正确的是( )
A.通过最小二乘法得到的线性回归直线经过样本的中心 |
B.用最小二乘法求回归直线方程,是寻求使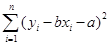 最小的a,b的值 最小的a,b的值 |
| C.相关系数r越小,表明两个变量相关性越弱 |
D. 越接近1,表明回归的效果越好 越接近1,表明回归的效果越好 |
在建立两个变量 与
与 的回归模型中,分别选择了4个不同的模型,它们的相关指数
的回归模型中,分别选择了4个不同的模型,它们的相关指数 如下,其中拟合最好的模型是( )
如下,其中拟合最好的模型是( )
| A.模型1的相关指数为0.98 | B.模型2的相关指数为0.80 |
| C.模型3的相关指数为0.50 | D.模型4的相关指数为0.25 |
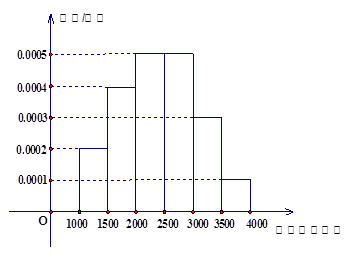
一个容量为35的样本数据,分组后,组距与频数如下: 个;
个; 个;
个; 个;
个; 个;
个; 个;
个;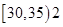 个。则样本在区间
个。则样本在区间 上的频率为
上的频率为
| A.20% | B.69% | C.31% | D.27% |
对变量 有观测数据(
有观测数据( ,
, )(
)( ),得散点图1;对变量
),得散点图1;对变量 有观测数据(
有观测数据( ,
, )(i=1,2,…,10),得散点图2. 由这两个散点图可以判断
)(i=1,2,…,10),得散点图2. 由这两个散点图可以判断
| A.变量x 与y 正相关,u 与v 正相关 | B.变量x 与y 正相关,u 与v 负相关 |
| C.变量x 与y 负相关,u 与v 正相关 | D.变量x 与y 负相关,u 与v 负相关 |
随机抽取某中学甲、乙两面个班10名同学,测量他们的身高(单位:cm)后获得身高数据的茎叶图如图甲所示,在这20人中,记身高在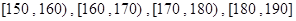 内的人数依次为
内的人数依次为 ,图乙是统计样本中身高在一定范围内的人数的算法流程图,则下列说法正确的是( )
,图乙是统计样本中身高在一定范围内的人数的算法流程图,则下列说法正确的是( )



| A.由图甲可知甲、乙两班中身高的中位数较大的是甲班,图乙输出的S的值为18 |
| B.由图甲可知甲、乙两班中身高的中位数较大的是乙班,图乙输出的S的值为18 |
| C.由图甲可知甲、乙两班中身高的中位数较大的是乙班,图乙输出的S的值为16 |
| D.由图甲可知甲、乙两班中身高的中位数较大的是甲班,图乙输出的S的值为16 |
 ,净重大于等于15克且小于17克的产品数为
,净重大于等于15克且小于17克的产品数为 ,则从频率分布直方图中可分析出
,则从频率分布直方图中可分析出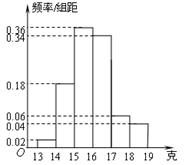




 (元)段中抽取了30人,则在这20000人中共抽取的人数为( )
(元)段中抽取了30人,则在这20000人中共抽取的人数为( )