(四)、举例:
例1.在某医院,因为患心脏病而住院的 665 名男性病人中,有 214 人秃顶,而另外 772 名不是因为患心脏病而住院的男性病人中有 175 人秃顶.
(1)利用图形判断秃顶与患心脏病是否有关系.
(2)能够以 99 %的把握认为秃顶与患心脏病有关系吗?为什么?
解:根据题目所给数据得到如下列联表:
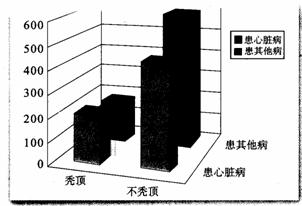
(1)相应的三维柱形图如图3.2一4所示.比较来说,底面副对角线上两个柱体高度的乘积要大一些,可以在某种程度上认为“秃顶与患心脏病有关”.
(2)根据列联表3一11中的数据,得到
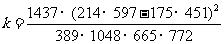 ≈16.373>6 .
≈16.373>6 .
因此有 99 %的把握认为“秃顶与患心脏病有关” .
例2.为考察高中生的性别与是否喜欢数学课程之间的关系,在某城市的某校高中生中随机抽取300名学生,得到如下列联表:
表3一12 性别与喜欢数学课程列联表
|
|
喜欢数学课程 |
不喜欢数学课程 |
总计 |
|
男 |
37 |
85 |
122 |
|
女 |
35 |
143 |
178 |
|
总计 |
72 |
228 |
300 |
由表中数据计算得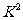 的观测值
的观测值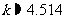 .能够以95%的把握认为高中生的性别与是否喜欢数学课程之间有关系吗?请详细阐明得出结论的依据.
.能够以95%的把握认为高中生的性别与是否喜欢数学课程之间有关系吗?请详细阐明得出结论的依据.
解:可以有约95%以上的把握认为“性别与喜欢数学课之间有关系”.作出这种判断的依据是独立性检验的基本思想,具体过程如下:
分别用a , b , c ,
d 表示样本中喜欢数学课的男生人数、不喜欢数学课的男生人数、喜欢数学课的女生人数、不喜欢数学课的女生人数.如果性别与是否喜欢数学课有关系,则男生中喜欢数学课的比例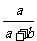 与女生中喜欢数学课的人数比例
与女生中喜欢数学课的人数比例 应该相差很多,即
应该相差很多,即
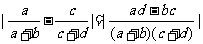
应很大.
将上式等号右边的式子乘以常数因子
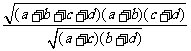 ,
,
然后平方得
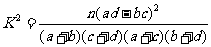 ,
,
其中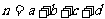 .因此越大,“性别与喜欢数学课之间有关系”成立的可能性越大.
.因此越大,“性别与喜欢数学课之间有关系”成立的可能性越大.
另一方面,在假设“性别与喜欢数学课之间没有关系”的前提下,事件A ={≥3.
841}的概率为P (≥3.
841) ≈0.05,
因此事件 A 是一个小概率事件.而由样本数据计算得的观测值k=4.514,即小概率事件 A发生.因此应该断定“性别与喜欢数学课之间有关系”成立,并且这种判断结果出错的可能性约为5 %.所以,约有95 %的把握认为“性别与喜欢数学课之间有关系”.
补充例题1:打鼾不仅影响别人休息,而且可能与患某种疾病有关,下表是一次调查所得的数据,试问:每一晚都打鼾与患心脏病有关吗?
|
|
患心脏病 |
未患心脏病 |
合计 |
|
每一晚都打鼾 |
30 |
224 |
254 |
|
不打鼾 |
24 |
1355 |
1379 |
|
合计 |
54 |
1579 |
1633 |
解:略。
补充例题2: 对196个接受心脏搭桥手术的病人和196个接受血管清障手术的病人进行3年跟踪研究,调查他们是否又发作过心脏病,调查结果如下表所示:
|
|
又发作过心脏病 |
未发作过心脏病 |
合计 |
|
心脏搭桥手术 |
39 |
157 |
196 |
|
血管清障手术 |
29 |
167 |
196 |
|
合计 |
68 |
324 |
392 |
试根据上述数据比较两种手术对病人又发作心脏病的影响有没有差别。
解略
对于性别变量,其取值为男和女两种.这种变量的不同“值”表示个体所属的不同类别,像这类变量称为分类变量.在现实生活中,分类变量是大量存在的,例如是否吸烟,宗教信仰,国籍,等等.在日常生活中,我们常常关心两个分类变量之间是否有关系.例如,吸烟与患肺癌是否有关系?性别对于是否喜欢数学课程有影响?等等.
为调查吸烟是否对肺癌有影响,某肿瘤研究所随机地调查了9965人,得到如下结果(单位:人)
表3-7 吸烟与肺癌列联表
|
|
不患肺癌 |
患肺癌 |
总计 |
|
不吸烟 |
7775 |
42 |
7817 |
|
吸烟 |
2099 |
49 |
2148 |
|
总计 |
9874 |
91 |
9965 |
那么吸烟是否对患肺癌有影响吗?
像表3一7 这样列出的两个分类变量的频数表,称为列联表.由吸烟情况和患肺癌情况的列联表可以粗略估计出:在不吸烟者中,有0.54 %患有肺癌;在吸烟者中,有2.28%患有肺癌.因此,直观上可以得到结论:吸烟者和不吸烟者患肺癌的可能性存在差异.
与表格相比,三维柱形图和二维条形图能更直观地反映出相关数据的总体状况.图3. 2 一1 是列联表的三维柱形图,从中能清晰地看出各个频数的相对大小.
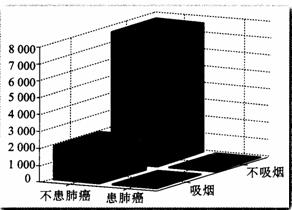
图3.2一2 是叠在一起的二维条形图,其中浅色条高表示不患肺癌的人数,深色条高表示患肺癌的人数.从图中可以看出,吸烟者中患肺癌的比例高于不吸烟者中患肺癌的比例.
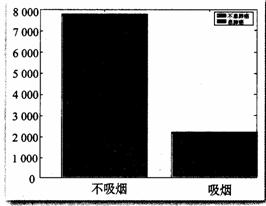
为了更清晰地表达这个特征,我们还可用如下的等高条形图表示两种情况下患肺癌的比例.如图3.2一3 所示,在等高条形图中,浅色的条高表示不患肺癌的百分比;深色的条高表示患肺癌的百分比.
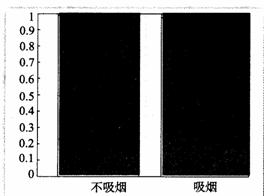
通过分析数据和图形,我们得到的直观印象是“吸烟和患肺癌有关”.那么我们是否能够以一定的把握认为“吸烟与患肺癌有关”呢?
为了回答上述问题,我们先假设
H0:吸烟与患肺癌没有关系.用A表示不吸烟, B表示不患肺癌,则“吸烟与患肺癌没有关系”独立”,即假设 H0等价于
PAB)=P(A)+P(B) .
把表3一7中的数字用字母代替,得到如下用字母表示的列联表:
表3-8 吸烟与肺癌列联表
|
|
不患肺癌 |
患肺癌 |
总计 |
|
不吸烟 |
a |
b |
a+b |
|
吸烟 |
c |
d |
c+d |
|
总计 |
a+c |
b+d |
a+b+c+d |
在表3一8中,a恰好为事件AB发生的频数;a+b 和a+c恰好分别为事件A和B发生的频数.由于频率近似于概率,所以在H0成立的条件下应该有
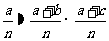 ,
,
其中为样本容量, (a+b+c+d)≈(a+b)(a+c) ,
即ad≈bc.
因此,|ad-bc|越小,说明吸烟与患肺癌之间关系越弱;|ad -bc|越大,说明吸烟与患肺癌之间关系越强.
为了使不同样本容量的数据有统一的评判标准,基于上面的分析,我们构造一个随机变量
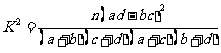 (1)
(1)
其中为样本容量.
若 H0 成立,即“吸烟与患肺癌没有关系”,则 K “应该很小.根据表3一7中的数据,利用公式(1)计算得到 K “的观测值为
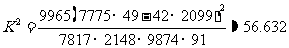 ,
,
这个值到底能告诉我们什么呢?
统计学家经过研究后发现,在 H0成立的情况下,
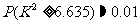 .
(2)
.
(2)
(2)式说明,在H0成立的情况下,的观测值超过 6. 635 的概率非常小,近似为0 . 01,是一个小概率事件.现在的观测值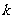 ≈56.632
,远远大于6. 635,所以有理由断定H0不成立,即认为“吸烟与患肺癌有关系”.但这种判断会犯错误,犯错误的概率不会超过0.01,即我们有99%的把握认为“吸烟与患肺癌有关系” .
≈56.632
,远远大于6. 635,所以有理由断定H0不成立,即认为“吸烟与患肺癌有关系”.但这种判断会犯错误,犯错误的概率不会超过0.01,即我们有99%的把握认为“吸烟与患肺癌有关系” .
在上述过程中,实际上是借助于随机变量的观测值建立了一个判断H0是否成立的规则:
如果≥6.
635,就判断H0不成立,即认为吸烟与患肺癌有关系;否则,就判断H0成立,即认为吸烟与患肺癌没有关系.
在该规则下,把结论“H0 成立”错判成“H0 不成立”的概率不会超过
,
即有99%的把握认为从不成立.
上面解决问题的想法类似于反证法.要确认是否能以给定的可信程度认为“两个分类变量有关系”,首先假设该结论不成立,即
H0:“两个分类变量没有关系”
成立.在该假设下我们所构造的随机变量应该很小.如果由观测数据计算得到的的观测值k很大,则在一定可信程度上说明H0不成立,即在一定可信程度上认为“两个分类变量有关系”;如果k的值很小,则说明由样本观测数据没有发现反对H0 的充分证据.
怎样判断的观测值 k 是大还是小呢?这仅需确定一个正数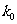 ,当
,当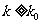 时就认为 的观测值k大.此时相应于的判断规则为:
时就认为 的观测值k大.此时相应于的判断规则为:
如果,就认为“两个分类变量之间有关系”;否则就认为“两个分类变量之间没有关系”.
我们称这样的为一个判断规则的临界值.按照上述规则,把“两个分类变量之间没有关系”错误地判断为“两个分类变量之间有关系”的概率为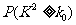 .
.
在实际应用中,我们把解释为有 的把握认为“两个分类变量之间有关系”;把
的把握认为“两个分类变量之间有关系”;把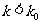 解释为不能以的把握认为“两个分类变量之间有关系”,或者样本观测数据没有提供“两个分类变量之间有关系”的充分证据.上面这种利用随机变量来确定是否能以一定把握认为“两个分类变量有关系”的方法,称为两个分类变量的独立性检验.
解释为不能以的把握认为“两个分类变量之间有关系”,或者样本观测数据没有提供“两个分类变量之间有关系”的充分证据.上面这种利用随机变量来确定是否能以一定把握认为“两个分类变量有关系”的方法,称为两个分类变量的独立性检验.
利用上面结论,你能从列表的三维柱形图中看出两个变量是否相关吗?
一般地,假设有两个分类变量X和Y,它们的可能取值分别为{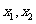 }和{
}和{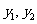 }, 其样本频数列联表(称为2×2列联表)为:
}, 其样本频数列联表(称为2×2列联表)为:
表3一 9 2×2列联表
|
|
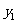 |
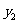 |
总计 |
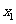 |
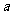 |
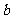 |
 |
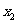 |
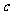 |
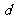 |
 |
|
总计 |
 |
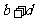 |
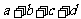 |
若要推断的论述为
Hl:X与Y有关系,
可以按如下步骤判断结论Hl 成立的可能性:
1.通过三维柱形图和二维条形图,可以粗略地判断两个分类变量是否有关系,但是这种判断无法精确地给出所得结论的可靠程度.
① 在三维柱形图中,主对角线上两个柱形高度的乘积ad 与副对角线上的两个柱形高度的乘积bc相差越大,H1成立的可能性就越大.
② 在二维条形图中,可以估计满足条件X=的个体中具有Y=的个体所占的比例,也可以估计满足条件X=的个体中具有Y=,的个体所占的比例.“两个比例的值相差越大,Hl 成立的可能性就越大.
2.可以利用独立性检验来考察两个分类变量是否有关系,并且能较精确地给出这种判断的可靠程度.具体做法是:
① 根据实际问题需要的可信程度确定临界值;
② 利用公式( 1 ) ,由观测数据计算得到随机变量的观测值;
③ 如果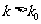 ,就以的把握认为“X与Y有关系”;否则就说样本观测数据没有提供“X与Y有关系”的充分证据.
,就以的把握认为“X与Y有关系”;否则就说样本观测数据没有提供“X与Y有关系”的充分证据.
在实际应用中,要在获取样本数据之前通过下表确定临界值:
表3一10
|
|
0.50 |
0.40 |
0.25 |
0.15 |
0.10 |
0.05 |
0.025 |
0.010 |
0.005 |
0.001 |
|
|
0.455 |
0.708 |
1.323 |
2.072 |
1.323 |
2.706 |
3.841 |
5.024 |
6.635 |
10.828 |